
 18 enero, 2019
18 enero, 2019
La cantidad de data generada diariamente supera la capacidad del ser humano de recopilar y analizar es un hecho.
Hoy en día existen conocimientos informáticos y estadísticos para usar la tecnología y enfocarla en la recopilación, gestión y medición de dicha cantidad de datos.
Un algoritmo es básicamente una regla abstracta que permite encontrar y expresar aquello que buscamos (en el mundo del big data, generalmente la búsqueda de patrones y relaciones entre variables).
Estos algoritmos son desarrollados con el único objetivo de automatizar un camino óptimo que ayude al ser humano a tratar la ingente cantidad de datos que se genera diariamente.
De hecho, los algoritmos, junto con el hardware y las redes constituyen los tres pilares sobre los que sustenta la transformación digital de las empresas.
Valorizar la información de una empresa incluida en grandes depósitos de datos es uno de los objetivos más conocidos del data mining.
Pero las potencialidades de las técnicas, de las metodologías y de los ejemplos que forman parte de la definición de data mining van mucho más allá de la simple valorización de datos.
En Velogig, creemos que en esta transformación digital es imperativo el uso de la ciencia de datos, por ello, hemos recopilado 10 algoritmos que nosotros utilizamos para el análisis de datos de nuestros clientes.
Con estos algoritmos, se puede potenciar y refinar tu estrategia de marketing y destacar de la competencia.
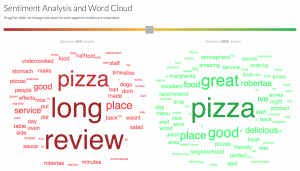
1.- Word Cloud (Análisis de sentimiento)
Podemos definir el análisis sentimental (“Sentiment Analysis”) aplicado al mundo Web como el “tratamiento computacional de las opiniones, sentimientos y fenómenos subjetivos en los textos”.
Dicho de otro modo: a partir de un algoritmo, un programa es capaz de entender, interpretar, discernir y traducir el significado (polaridad) de un texto digital haciéndolo operativo para su análisis y ordenarlo y clasificarlos en objetivo / subjetivo; y dentro de los subjetivos, en positivos o negativos.
El valor creciente que está adquiriendo el “Sentiment Analysis” viene determinado por las múltiples utilidades para la actividad de empresas y organizaciones en diferentes áreas, pero especialmente en la de marketing y seguimiento de la presencia en internet, en los medios sociales.
Cada una de estas utilidades o aplicaciones aporta un valor añadido importante, y en muchos casos mesurable.
2.- Ordinal regression
El concepto de regresión hace referencia a dar un paso atrás, volver a un estado anterior. En informática y estadística, la regresión es una herramienta muy útil para realizar proyecciones futuras o estimaciones.
Prever el futuro es el sueño de cualquier profesional de marketing.
Empleando el análisis regresivo o de regresión, podemos predecir datos futuros a partir de series antiguas históricas. Cuanto más exacta sea la ecuación obtenida mediante la regresión, más fiable será esa predicción.
Es por ello que es necesario tener, por un lado, una gran cantidad de datos observados, esto aplicado a las empresas permite hacer previsiones de ventas, ingresos, o evolución de mercados, estudiar cambios, costumbres, nivel de satisfacción de los clientes y otros factores relacionados con parámetros como el presupuesto de una campaña publicitaria o similares.
3.- Time Series
Un time series analysis o análisis de series temporales es una forma de medir a través de variables como la tendencia, el ciclo o la estacionalidad los valores futuros dentro del mercado.
Las estimaciones no sólo deben de hacerse desde la perspectiva de la marca, también puede aplicarse desde el punto de vista del consumidor y de la naturaleza misma del mercado como el consumo o las situaciones geopolíticas que colocan los marcadores en cero, cuando estos ya habían marcado estimados en ganancias, valores de marca, tendencias de consumo, precios y expectativa de gasto, entre otros elementos.
Esto puede permitir desde conocer el valor de tu marca a lo largo del tiempo y su evolución, como generar perfiles de consumo para comparar el crecimiento de las operaciones de venta.
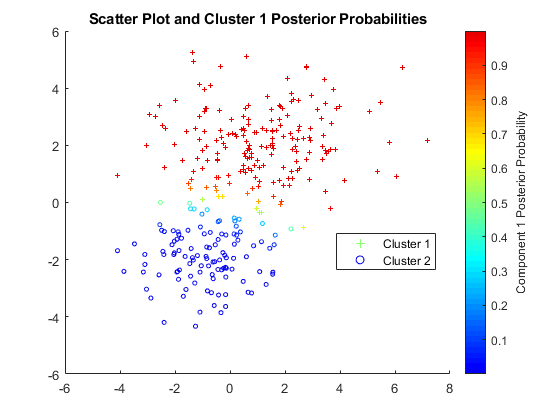
4.- Cluster analysis
Más conocido como algoritmo de agrupamiento (en inglés, clustering), el análisis cluster permite identificar dentro de un archivo un determinado grupo de usuarios según características comunes.
Estas características pueden ser la edad, la procedencia geográfica, el título de estudio, etc. Las combinaciones de variables son infinitas y hacen que el análisis cluster sea más o menos selectivo según las exigencias de búsqueda.
Se trata de una técnica de data mining que en el marketing es útil para segmentar la base de datos y enviar, por ejemplo, una cierta promoción al objetivo apropiado para ese producto o servicio (jóvenes, madres, jubilados, etc.).
5.- Decision Tree Regression
Cada vez que tomas una decisión estás en una encrucijada. Cuando hay muchas opciones en vez de la encrucijada tienes un árbol de decisión.
En principio tener que ver con un árbol de este tipo confunde las ideas, pero si tenemos una herramienta informática que organiza el árbol y nos somete a elecciones definitivas, incluidos costes/beneficios, la cosa cambia y el mismo árbol se convierte en una valiosa herramienta para el manejo de riesgos.
También en este caso la profundidad de análisis depende en gran medida de la tecnología disponible: cuanto más avanzado es el software, más sabrá indicarte el árbol cuál es el mejor camino a seguir.
6.- Neural Networks Regression
Complementar el clustering y los árboles de decisión es el concepto de red neuronal. Es una de las aplicaciones más recientes del data mining según la cual la máquina que utilizas para tus acciones de marketing, y por tanto el ordenador que gestiona tu base de datos, “aprende” a identificar un determinado patrón en cuyo interior hay elementos con relaciones concretas entre sí.
El resultado de este “aprendizaje“(machine learning) es el reconocimiento y la memorización de esquemas que pueden volverse útiles, quizás no en seguida pero sí en el futuro, para decidir si y cómo alcanzar un objetivo.
La misma red neuronal puede ayudarte a conocer con mayor exactitud la composición del objetivo de un producto o servicio.
7.- Anomaly Detection
Cada negocio, por grande o pequeño que sea, tiene que afrontar a diario las consecuencias de posibles errores cometidos por empleados, proveedores o clientes.
Un insignificante descuido durante la fase de introducción de datos o en la adquisición de un producto tiene el mismo efecto que una piedra en el zapato. Nada del otro mundo pero que de todas formas molesta.
Para eliminar radicalmente incongruencias y anomalías de la base de datos se recurre a una técnica de data mining especial que se llama anomaly detection.
También en este caso gestionará la búsqueda nuestro software, programado para realizar operaciones complejas en bases de datos que contienen hasta cientos de millones de registros (direcciones, nombres, etc.).
8.- Association Rule Learning
La utilización común del association rule learning concierne a las actividades de venta de productos, en especial para grandes volúmenes.
Tanto si es online a través de un e-commerce o en persona en una tienda (o un centro comercial), se crean relaciones interesantes entre los datos que posees. Relaciones que no sospechabas o que ni siquiera te imaginabas.
Por ejemplo: El 90% de los clientes que compran online un producto también compran otro, siempre lo mismo. Detalles que nos permiten crear ofertas de marketing específicas, promociones especiales y fórmulas exitosas.
9.- Rule Induction
Si se produce una circunstancia determinada y otra y otra, entonces conseguimos este resultado. Más o menos la regla de la inducción funciona así.
Y no es poco: gracias a esta técnica de data mining puedes realizar sofisticados análisis predictivos pescando dentro de bases de datos con números de miles y miles de registros.
Identificar regularidades ocultas quiere decir anticipar los tiempos y actuar con conocimiento de causa, algo que a menudo tus competidores se olvidan de hacer.
10.- Data Warehousing
El último algoritmo que mencionaremos, pero quizás sería más correcto llamarla aplicación, se llama data warehousing.
Aquí entramos en el ámbito de la creación del perfil del cliente (y no solo), en especial respecto al tratamiento de Big Data.
Elegir un algoritmo para el data warehousing quiere decir simplificar las bases de datos, extrapolar la información más interesante sobre tus clientes, facilitar la elaboración de informes detallados y mucho más.
En la migración de software y sistemas poder contar con software de data warehouse resulta aún más importante, antes que para el marketing para la evolución de la empresa en sí.



Deja una respuesta