
 28 septiembre, 2018
28 septiembre, 2018
Nos encontramos en una era en donde a cada segundo se van creando grandes volúmenes de datos. Y con ello la aparición de nuevos conceptos asociados a ellos.
Muchas veces hemos escuchado la palabra Machine Learning. Y lo primero que se nos viene a la mente es: “debe tener relación con Data Science, Data Scientist, Data Mining, Inteligencia Artificial o Big Data”.
Si bien cada uno de los términos mencionados parecerían tener relación. Existen diferencias en cuanto a concepto, origen y utilidad.
Antes de empezar a hablar de Machine Learning y cómo es su proceso, es oportuno poder realizar esta diferenciación.
1.- Un pequeño glosario antes de empezar
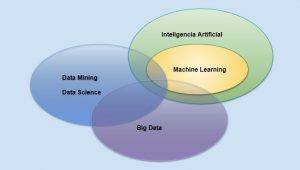
Empecemos hablando sobre Data Science, entendámoslo como un conjunto de principios, procesos y técnicas que guían la extracción de conocimiento desde la data con el objetivo de mejorar la toma de decisiones.
En cuanto al Data Mining, es la extracción de conocimiento desde la data a través de tecnologías que incorporan los principios de Data Science.
Asimismo, cuando hablemos de Big Data, diremos que es un conjunto de datos que son muy largos para ser analizados bajo un sistema de procesamiento tradicional, y que requiere nuevas tecnologías de procesamiento.
Por Inteligencia artificial, recurriremos a John McCarthy quien acuñó este nombre por primera vez en 1956. Y lo definió como “la ciencia e ingenio de hacer máquinas inteligentes”. Es decir, tener computadoras con la habilidad de razonar como humanos.
Dado los conceptos anteriores, la siguiente pregunta sería: ¿Quién es la persona idónea para trabajar con el big data, utilizar los principios de Data Science, así como la extracción de conocimiento de la data? La respuesta: un data scientist, por ello es importante considerar las diferencias entre Machine learning y Big Data.
Un data scientist es un profesional con capacidades de analítica, estadística y programación. Las cuales utiliza para recolectar, analizar e interpretar gran cantidad de datos con el objetivo de mejorar la toma de decisiones.
2.- Definiendo Machine Learning
El aprendizaje de máquina o Machine Learning es un subconjunto de la inteligencia artificial. Donde las computadoras tienen la habilidad de aprender sin ser programadas. Es decir, no requiere de una persona que programe dichas instrucciones.
Las computadoras reciben un conjunto de datos y aprenden por sí mismos. Busca patrones entre los datos y realiza predicciones.
Es aquí donde resulta pertinente hacer una diferenciación entre Machine Learning y Data Mining. Términos que comúnmente son considerados como sinónimos.
Históricamente Data Mining se separó de Machine Learning como un campo de investigación centrado en las inquietudes del mundo real. Es decir, se enfoca en la búsqueda de conocimiento.
Ambos campos están relacionados con el análisis de datos con el objetivo de encontrar patrones útiles o informativos. Incluso utilizan las mismas técnicas y algoritmos.
Podríamos decir, que la diferencia principal radica en que en Data Mining , la participación humana es vital y sin ella no puede funcionar. En cuanto a Machine Learning el esfuerzo humano se realiza sólo al momento de crear el algoritmo.

3.- El proceso de Machine Learning
Machine learning debemos verlo como un proyecto. Y como tal, requiere de procesos o etapas para llegar al objetivo propuesto.
A continuación, mencionaremos las etapas a tener cuenta si deseamos emprender el camino de Machine Learning:
Etapa 1: Definir el objetivo
Es vital entender el problema a resolver. Debemos ser objetivos en cuanto a nuestro objetivo dado las características de la empresa, así como de la data que tendremos a disposición.
Recordemos que Machine Learning tiene como insumo principal la data.
Las siguientes preguntas son típicas en esta etapa:
- ¿Qué exactamente deseamos hacer?
- ¿Cómo exactamente podremos hacerlo?
- ¿Es posible lo que deseo dada la data que tengo?

Etapa 2: Recolección de la data
Luego de definir nuestro objetivo. Procedemos a la recolección de la data. Recordemos que nuestro algoritmo de Machine Learning necesita de ella.
Esta etapa resulta ser fácil si estamos frente a una empresa ordenada en cuanto al proceso de recolección.
Es importante entender las fortalezas y limitaciones de la data. Porque pocas veces estas coincidirán con el problema a resolver.
Asimismo, recordemos que no necesariamente tendremos toda la data necesaria para resolver el problema en nuestro sistema. Tendremos en algunos casos que recurrir a sistemas externos, que pueden ser cero costo.
Y en otros casos tendremos que comprar la data. O simplemente no será posible acceder porque no existen.

Etapa 3: Preparar la data
Una vez que disponemos de la data continuamos con el preprocesamiento de la misma, esto normalmente lo conocemos como la limpieza de los datos, el formateo.
El objetivo de esta etapa es manipular y convertir la data en formas que produzcan mejores resultados.
Como ejemplos típicos de preparación de datos tenemos: eliminar o inferir datos perdidos, categorizar los valores de las variables, normalizar los valores numéricos o escalarlos para que puedan ser comparables.

Etapa 4: Elección del algoritmo
Una vez que ya hemos preprocesado la data nos corresponde elegir el algoritmo más adecuado en relación al problema que deseamos resolver.
Es aquí donde debemos optar por un algoritmo de aprendizaje supervisado o un aprendizaje no supervisado.
Dentro de los algoritmos de aprendizaje supervisado tenemos: Linear Regression, Logistic Regression, Decision Tree Regression, K-Nearest Neighbors (KNN), Support Vector Machine (SVM), Decision Tree Classification, etc.
Dentro de los algoritmos de aprendizaje no supervisado tenemos: K-Means Clustering, Hierarchical Clustering, Principal Component Analysis, etc.

Etapa 5: Entrenar el modelo
Elegido el algoritmo procedemos a separar la data preprocesada. Un porcentaje de la data, comúnmente el 70 % del total, la utilizaremos como data de entrenamiento.
Es decir, será aquella a la cual aplicaremos el algoritmo seleccionado. Sobre esta data buscaremos alcanzar el objetivo planteado inicialmente.

Etapa 6: Validación del modelo
Dado que ya tenemos el modelo entrenado, lo siguiente es validarlo. Esto lo realizaremos con la data restante, aquella que no utilizamos para el entrenamiento. La cual llamaremos data de validación.
Sobre la data de validación procederemos a correr el algoritmo y a evaluar los resultados obtenidos.
Debemos ser conscientes que existe la posibilidad que el modelo funcione bien para la data de entrenamiento y no para la data de validación (problema de overfitting).
Por tal cabe resaltar que volveremos a la etapa 6 hasta que nuestro modelo se ajuste bien a las dos particiones (data de entrenamiento y data de validación). Todo esto con el propósito de ganar confianza en nuestro modelo.

Etapa 7: Predicción
Una vez que nuestro modelo haya superado el problema de overfitting, el siguiente paso es realizar la predicción. La cual obtendremos al ingresar nueva data a nuestro modelo.

Asimismo, también podría interesarte estos libros sobre Machine Learning,además de este artículo sobre la influencia del Machine Learning en las estrategias de redes sociales.



Deja una respuesta