
 25 junio, 2020
25 junio, 2020
Google Analytics como plataforma no se creó desde cero para ser una herramienta de ciencia de datos.
Sin embargo, las necesidades de un análisis más avanzado han ido evolucionando rápidamente y generando nuevas expectativas.
Gracias a la disponibilidad de una API sólida y una serie de técnicas de transformación de datos, los datos de Google Analytics ahora se pueden utilizar como entrada en poderosos algoritmos de extracción de datos / aprendizaje automático.
El objetivo es cubrir todos los pasos necesarios hasta que los datos de Google Analytics estén listos para la ciencia de datos.
La intención es proponer un marco que sirva de guía, especialmente para los analistas que exploran nuevas formas de realizar trabajos de análisis con sus datos de Google Analytics.
Paso 1: Acceda a los datos a través de la API de Google Analytics
El acceso eficiente a los datos es crítico para cada análisis, especialmente cuando queremos que sea reproducible o apunte a construir aplicaciones de datos que dependan de la automatización.
La API de Google Analytics es robusta, está bien documentada y se desarrolla continuamente, no todas las API en la web son así.
El primer paso es, por lo tanto, asegurar el acceso a la API. La buena noticia para el analista es que tanto R (por ejemplo, googleAnalyticsR) como Python (google2pandas) disponen de bibliotecas de código abierto que pueden hacer el trabajo pesado al:
- Simplificando el proceso de autentificación.
- Llamando a la API con la petición.
- Recibir la respuesta en un formato con el que es fácil trabajar de inmediato (generalmente un marco de datos)
En muchos sentidos, el proceso restante para el analista se convierte en algo parecido a escribir una consulta SQL simple.
Paso 2: Seleccionar variables
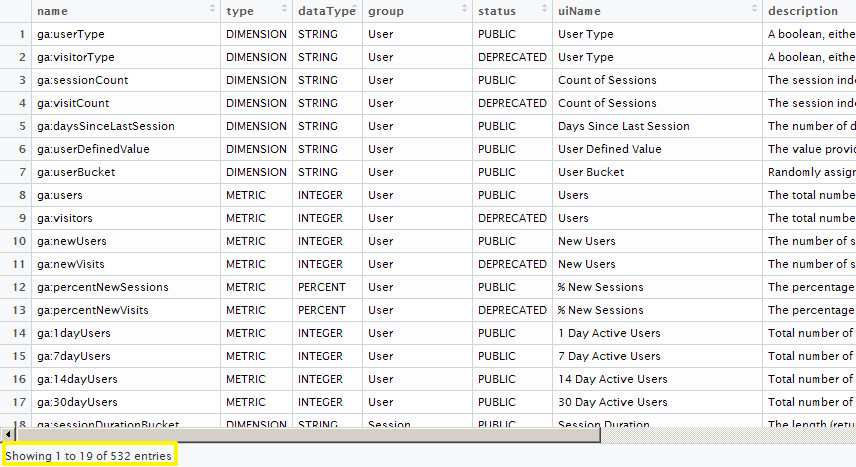
Una vez que accedemos a la API, una simple llamada a una función puede devolver todas las métricas y dimensiones disponibles. Hay cientos de ellas para seleccionar, incluso aunque no todas son accesibles para todas las cuentas.
En cuanto a la calidad, los datos normalmente vienen limpios, estructurados en forma tabular, mientras que los casos de valor faltante son relativamente raros.
Vale la pena recordar que esos atributos atractivos no siempre están presentes en otras industrias, utilizando diferentes tipos de fuentes de datos.
Por lo tanto, cuando se trata de acceso y variedad en los datos, con Google Analytics API podemos marcar casi todos los recuadros.
Pero luego empezamos a enfrentar algunos retos. El primero es el muestreo de datos.
Paso 3: Desmuestrear los datos

Ya sea que usemos Google Analytics a través de la interfaz de usuario o la API, todos hemos experimentado la muestra de nuestros datos de informe. Obtener datos muestreados no es el fin del mundo, pero para ciertos tipos de análisis, puede ser un problema. Entonces, ¿se puede evitar y cómo?
La razón por la que se produce el muestreo es que una solicitud rompe los límites de sesión superiores establecidos por Google Analytics.
Por lo tanto, una forma de evitarlo es dividir el período de tiempo que corresponde a los segmentos más pequeños que no harán que se excedan esos límites.
La biblioteca googleAnalyticsR es muy útil aquí, ya que funciona muy bien entre bambalinas; todo lo que necesita es la adición de un parámetro, como se resaltó anteriormente, en la llamada a la función normal.
Paso 4: Transformar

Los datos en forma agregada, que generalmente es lo que devuelve Google Analytics, no son óptimos para su uso como entrada para la minería de datos o algoritmos de aprendizaje automático.
Nuestro objetivo es llevar los datos de Google Analytics a forma granular para que prácticamente:
- Las filas corresponden a observaciones individuales, por ej. usuarios, sesiones o urls.
- Las columnas representan nombres de variables (es decir, métricas o dimensiones)
- Las celdas representan valores (números o niveles en el caso de variables categóricas)
En el mundo R, esta forma de organizar los datos suele denominarse datos ordenados.
También en Python se recomienda un formato bidimensional similar para los datos antes de, por ejemplo.
Se implementan los modelos scikit-learn (conocidos como matriz de características, donde las filas son para muestras y columnas para características).
– Explorador de usuarios
Actualmente, la única característica de Google Analytics que se acerca a esta idea es el explorador de usuarios.
Nos permite seguir a un usuario específico (cuyo ID de usuario correspondería a una fila en nuestra tabla ordenada) a través de todas las páginas visitadas / eventos activados en orden cronológico (las páginas visitadas y la marca de tiempo serían las columnas de nombre variable, de acuerdo con el marco ordenado).
Desafortunadamente, esta funcionalidad no se puede acceder a través de la API.
Sin embargo, ¡es obvio que los datos granulares que buscamos están realmente allí!
Entonces, ¿cómo podemos acceder a ellos programáticamente?
– Consultando múltiples dimensiones

Una forma de llegar a los datos de nivel granular es consultar la API para múltiples dimensiones simultáneamente.
El propósito de esto es generar un gran número de combinaciones para los diferentes niveles de cada dimensión combinadas entre sí.
Cada fila que se devuelve representa una porción tan delgada de tráfico que es poco probable que contenga más de una sesión (por lo tanto, las filas representan una observación, una sesión en ese caso).
El ejemplo anterior ilustra esto en el contexto de una tarea de predicción de conversión de un sitio web de comercio electrónico simulado.
Para un valor dado para cada una de las dimensiones seleccionadas, solo se contiene una sesión.
Potencialmente, y dependiendo de la elección de las dimensiones, podríamos terminar teniendo casos con dos o más sesiones contenidas, especialmente para sitios web de alto tráfico.
Sin embargo, es poco probable que esto suceda, dada la alta dimensionalidad de este ejemplo (se han utilizado las 7 ranuras API disponibles para la consulta de dimensiones).
– ID de cliente y marcas de tiempo
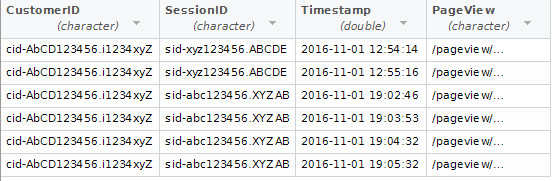
Un método alternativo para lograr la granularidad de los datos es a través de dimensiones personalizadas, p. Ej. ID de cliente combinado con marcas de tiempo.
Esto identificará de forma única cada vista de página o evento, asociándolo con un cliente específico, sesión y sello de tiempo como se ilustra arriba.
Este formulario es muy conveniente para examinar los viajes de los clientes, por ej. mediante la realización de análisis de flujo de clic.
El método de dimensiones personalizadas es probablemente el más sólido, pero requiere un trabajo de configuración adicional.
Paso opcional: almacenar los datos
Este paso es opcional y se trata más de seguir una buena práctica. Los conjuntos de datos tienden a ser cada vez más grandes en tamaño, pero a menudo solo necesitamos un subconjunto de los datos.
Tener todo el conjunto de datos almacenado localmente o en la nube puede ser útil si queremos probar el mismo análisis en diferentes rangos de fechas o tipos de clientes, por ejemplo.
En el contexto del análisis interactivo, la consulta de los datos a través de la base de datos hace que el proceso sea mucho más rápido en comparación con tener que ejecutar varias llamadas API.
La configuración de un proceso ETL para los datos de Google Analytics implica un poco más de trabajo al comienzo, pero está destinado a dar frutos a largo plazo.
Paso 5: Modelo
Ahora que hemos organizado los datos en la forma correcta, estamos listos para aplicar uno o más modelos de minería de datos o de aprendizaje automático y comenzar a ver los primeros resultados.
Dependiendo del algoritmo exacto, podría ser necesario eliminar los valores de NA, estandarizar / normalizar Los datos o realizar otros pasos de preprocesamiento.
El ejemplo ilustrado arriba es un árbol de decisión que predice la conversión o no conversión para una sesión determinada.
Y justo debajo de un gráfico de importancia variable se muestran los factores más importantes que afectan la conversión para un sitio web de comercio electrónico determinado; todo esto se basa en los datos de tabla de la sección 4.
La parte de modelado puede ser complicada, ya que se pueden dedicar innumerables horas a tratar de optimizar al máximo el rendimiento del modelo.
Sin embargo, en un contexto empresarial y especialmente cuando el resultado del análisis es para consumo humano, por ejemplo.
Para facilitar la toma de decisiones, existe un gran valor potencial en el uso de modelos simples pero potentes y, al mismo tiempo, interpretables.
Algunos buenos ejemplos de esto son árboles de decisión, modelos lineales, reglas de asociación o agrupación entre otros.
A menudo, incluso sin un ajuste de parámetros extenso, los resultados pueden ser lo suficientemente buenos como para ser útiles.



Deja una respuesta